
業務システムの開発をしていると、PDF編集処理が必要になることがあります。
PDFファイルへのテキストの出力、画像の埋め込み、枠や図形の描画など、帳票系の業務では特によく求められる機能ですよね。
オープンソースのPDFライブラリを探していたところ、PDFSharp が候補に上がりました。 ライセンスはMITで無償利用可能、.NETにも対応しており、最初は良い選択肢に見えました。
しかし実際に検証してみると、致命的な問題が発覚しました。
問題発覚:日本語フォントが使えない
PDFSharpを使って日本語テキストを出力しようとしたとき、エラーが発生しました。
原因を調査していくと、フォントの形式に問題があることが分かりました。
TTFとTTCの違い
日本語フォントには2つの形式があります。
| 形式 | 説明 | 代表例 |
|---|---|---|
| TTF(TrueType Font) | 1つのフォントが1つのファイルに収まっている | IPAex明朝、Noto Sans JP |
| TTC(TrueType Collection) | 複数のフォントを1つのファイルにまとめたもの | MS明朝、MSゴシック、メイリオ |
Windows標準の日本語フォントはほぼTTC形式です。
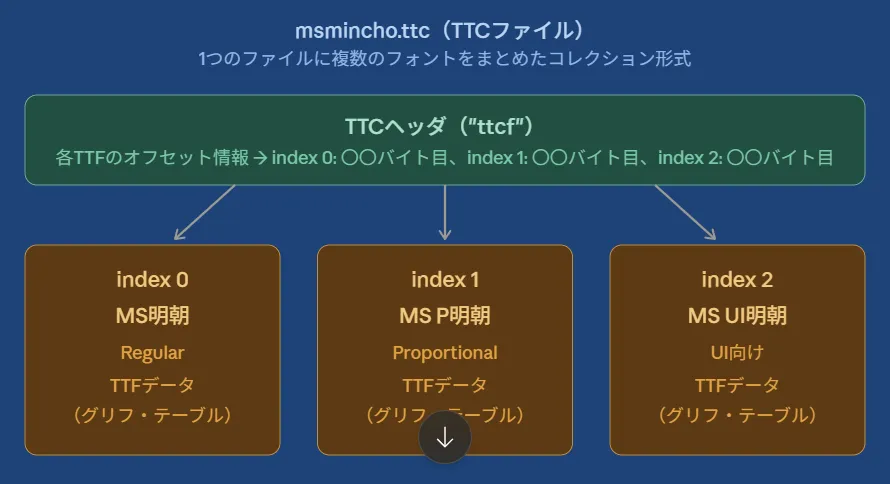
msmincho.ttc(1つのファイルの中に3つのフォントが入っている)
├── index 0: MS明朝
├── index 1: MS P明朝
└── index 2: MS UI明朝そしてPDFSharpはTTCフォントに対応していません。
エンドユーザーは「MS明朝」「MSゴシック」といった見慣れたフォントの使用を希望することが多いものです。
代替フォントへの切り替えは、業務帳票としての品質を落とすことになるため、現実的な解決策になりませんでした。
最初に考えた解決策とその問題点
案①:TTCファイルをTTFに変換して保存する
TTCファイルをTTFファイルに変換してしまえばPDFSharpで読み込めるのでは?と考えました。
実際にバイト列を解析してTTFとして保存する検証もしました。動作確認ではうまく動いたのです。「これで解決だ」と思いました。
しかし調査を進めると、フォントファイルの改造・再配布はライセンス違反になる可能性があることが判明しました。
MS明朝のようなWindowsフォントは、Microsoftのフォントライセンスに基づいて使用が許可されています。フォントファイル自体を改造して別の形式で保存・配布することは、このライセンスに抵触するリスクがあります。
せっかくうまくいったのに、この案は却下となりました。
案②:ライセンスがクリーンな代替フォントを使う
IPAexフォントやNoto JPフォントはOFLライセンスで埋め込みも自由です。技術的には問題なく使えます。
しかし業務システムでは、エンドユーザーが「MS明朝で見たい」と言うことが多く、見慣れたフォントへのこだわりは現実として存在します。
この案も現実的な解決策にはなりませんでした。
そして「自分で作ればいい」という気持ちに至った
2つの案が続けて却下になったとき、ふと思いました。
「PDFSharpがTTCに対応していないなら、自分でPDF編集DLLを作ってしまえばいいのではないか」
最初は無謀なアイデアかとも思いました。PDFの仕様は複雑で、フォントの埋め込みには専門知識が必要です。既存ライブラリを使うのが当然という意識もありました。
しかし考えれば考えるほど、自作するメリットが見えてきました。
そして何より、
「日本人開発者が日本語フォントで困らないDLLを、日本人が作る」
という動機が生まれました。
PDFSharpはすばらしいライブラリです。しかし日本語環境では壁がある。英語圏のライブラリに日本語対応を期待するより、自分たちで作った方が早い。
プログラマーとして20年以上業務システムを開発してきた経験を活かして、シンプルで、日本語に強く、VB.NETでもC#でも使えるPDF編集DLLを作ることにしました。
解決策:メモリ上でTTCをTTFとして展開する
調査を続けていくうち、重要なことに気づきました。
「フォントファイルの改造」がライセンスNGなのは、ファイルを書き換えて保存・再配布する場合です。
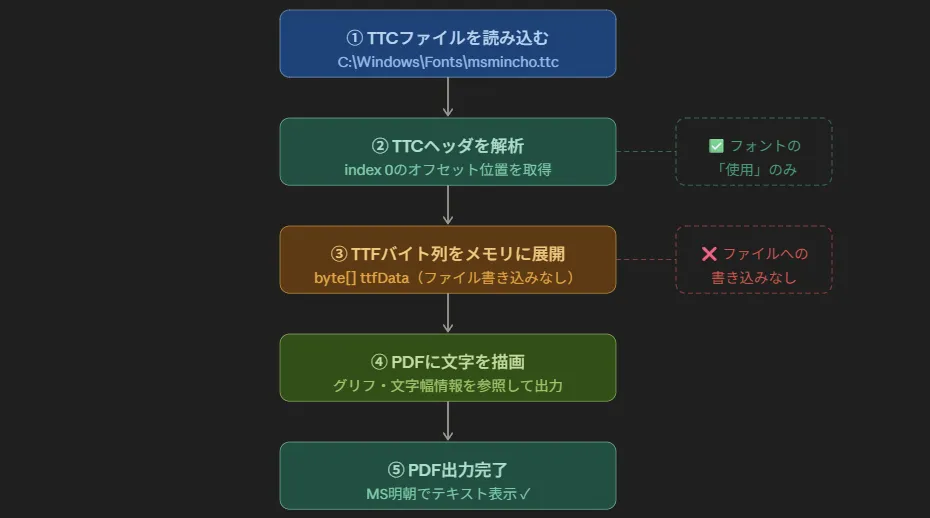
メモリ上で処理するだけなら話が変わります。
TTCファイルをそのまま読み込む(ファイルは一切書き換えない)
↓
メモリ上でTTFバイト列を取り出す
↓
そのバイト列をPDF生成処理に渡す
↓
ファイルへの書き込みなし・再配布なし
↓
「フォントを使用する」という行為の範囲内これならライセンス的に問題ありません。
TTCの内部構造
TTCファイルの構造はシンプルです。
TTCファイル
├── TTCヘッダ("ttcf"という識別子)
│ └── 各TTFのオフセット情報
├── TTF①(MS明朝)のデータ
├── TTF②(MS P明朝)のデータ
└── TTF③(MS UI明朝)のデータヘッダにある「オフセット情報」を読めば、目的のTTFデータがファイルのどの位置から始まるかが分かります。
TTFデータ読み込みのサンプル(C#)
public static byte[] LoadFontBytes(string fontPath, int ttcIndex = 0)
{
string ext = Path.GetExtension(fontPath).ToLower();
return ext switch
{
".ttc" => ExtractTtfFromTtc(fontPath, ttcIndex),
".ttf" => File.ReadAllBytes(fontPath),
_ => throw new PdfException($"未対応のフォント形式: {ext}")
};
}
private static byte[] ExtractTtfFromTtc(string ttcPath, int fontIndex)
{
byte[] ttcData = File.ReadAllBytes(ttcPath);
// TTCヘッダの検証(先頭4バイトが"ttcf"であること)
string tag = Encoding.ASCII.GetString(ttcData, 0, 4);
if (tag != "ttcf")
throw new PdfException("TTCファイルではありません");
// フォント数の取得(オフセット8)
int numFonts = ReadInt32BE(ttcData, 8);
if (fontIndex >= numFonts)
throw new PdfException("フォントインデックスが範囲外です");
// 対象フォントのオフセット取得(オフセット12 + index × 4)
int offset = ReadInt32BE(ttcData, 12 + fontIndex * 4);
// そのオフセット以降をTTFバイト列としてメモリに展開
int length = ttcData.Length - offset;
byte[] ttfData = new byte[length];
Array.Copy(ttcData, offset, ttfData, 0, length);
return ttfData; // ← ファイルには保存しない!メモリ上のみ
}ポイントはファイルへの書き込みを一切行わないことです。
メモリ上に展開したTTFバイト列をPDF生成処理にそのまま渡します。
VB.NETでの呼び出し例
' TTCでもTTFでも同じ呼び方
Dim fontBytes As Byte() = FontHelper.LoadFontBytes(
"C:\Windows\Fonts\msmincho.ttc", 0) ' index 0 = MS明朝さらに気づいたこと:フォント埋め込みのライセンス
実装を進める中で、もう一つ重要な問題を発見しました。
フォントファイルにはfsTypeというフラグが内部に格納されており、 PDFへの埋め込み可否を示しています。
| fsType値 | 意味 |
|---|---|
| 0x0000 | 埋め込み自由 |
| 0x0002 | 埋め込み禁止 |
| 0x0008 | 埋め込み許可 |
調査したところ、Windows 11のMS明朝・MSゴシックはfsType=0x0008(埋め込み許可)に更新されていました。
Microsoftが過去のバージョンから条件を緩和してくれていたのです。
このDLLでは、フォント読み込み時にfsTypeを自動チェックして 埋め込み可否を判定する機能も実装しています。
埋め込み可否判定のサンプル(C#)
// OS/2テーブルからfsTypeを読み取る
public static ushort GetFsType(byte[] ttfData)
{
int os2Off = FindTable(ttfData, "OS/2");
if (os2Off < 0 || os2Off + 10 > ttfData.Length) return 0;
return ReadU16(ttfData, os2Off + 8); // offset 8 = fsType
}完成したDLL「PdfUtility」
この仕組みをベースに、PDF編集DLL「PdfUtility」を開発しました。
主な機能
- ✅ TTC / TTF 両対応(MS明朝・MSゴシックをそのまま使用可能)
- ✅ テキスト・図形・枠・画像のPDF追記
- ✅ C# / VB.NET 対応
- ✅ インクリメンタルアップデート方式(既存PDFを壊さない)
- ✅ fsTypeによるフォント埋め込み可否の自動判定
使い方(C#)
var pdf = PdfUtilityFactory.Create();
pdf.Load("input.pdf");
pdf.ApplyCommands(new List<PdfDrawCommand>
{
new TextDrawCommand
{
PageNumber = 1,
X = 100, Y = 700,
Text = "承認済み",
FontName = "MS明朝",
FontSize = 12,
FontColor = PdfColor.Black
}
});
pdf.Save("output.pdf");使い方(VB.NET)
Dim pdf = PdfUtilityFactory.Create()
pdf.Load("input.pdf")
pdf.ApplyCommands(New List(Of PdfDrawCommand) From {
New TextDrawCommand With {
.PageNumber = 1,
.X = 100,
.Y = 700,
.Text = "承認済み",
.FontName = "MS明朝",
.FontSize = 12,
.FontColor = PdfColor.Black
}
})
pdf.Save("output.pdf")GitHubで公開しています
このDLLはMITライセンスでGitHubに公開しています。
🔗 https://github.com/Kunitaroo/PdfUtilitySolution
日本語のREADMEとサンプルコードを用意していますので、ぜひ使ってみてください。
まとめ
今回の開発で学んだことをまとめます。
| 問題 | 解決策 |
|---|---|
| PDFSharpがTTCフォントに非対応 | PDF生成ライブラリを自作 |
| フォントファイルの改造はライセンスNG | メモリ上でのみTTFを展開 |
| 埋め込み可否が不明 | fsTypeを自動チェック |
「既存のライブラリで解決できないなら自分で作る」という選択は、最初は大変に見えますが、Claude Codeを活用することで想像以上に短期間で実現できました。
業務でPDF編集にお困りの方はぜひGitHubのリポジトリをご覧ください!